Революция AI-десктопов: изменение роли процессоров ARM в локальных RAG-системах
AIoT Solutions
According to Arm Principal Solutions Architect Odin She’s article on Arm developers’ website:
「 «Переосмысление роли центрального процессора для AI: практическая реализация RAG-системы на базе платформы DGX Spark». 」
「 «Переосмысление роли центрального процессора для AI: практическая реализация RAG-системы на базе платформы DGX Spark». 」
Узкие места корпоративного поиска
Офлайновые RAG-системы стали главным решением для организаций, которые хотят устранить риски кибербезопасности и неточности, связанные с применением облачных LLM-моделей.
В корпоративных условиях критически важные данные, такие как спецификации, проектные руководства и оперативные заметки, часто оказываются фрагментированными по разным серверам, что делает традиционный поиск на основе ключевых слов неэффективным – из-за синонимов и расхождений в версиях. При этом выгрузка конфиденциальных данных в облачные LLM-модели часто противоречит политикам безопасности и нормативным требованиям, что приводит к росту спроса на локальные RAG-системы, работающие без подключения к интернету.
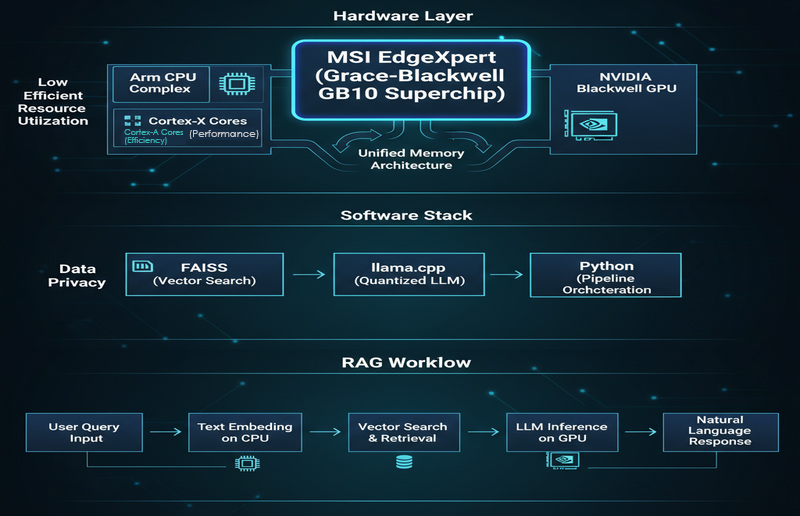
Минимальная архитектура для локальной RAG-системы
Функциональная десктопная RAG-система работает по определенному алгоритму, в рамках которого происходит преобразование исходных документов в проверяемые, сгенерированные искусственным интеллектом ответы.
Ее реализация в формате десктопной или периферийной системы обычно включает в себя следующие этапы:
- Очистка данных: Преобразование PDF-файлов, Word-документов и веб-страниц в единый формат и разбиение на блоки.
- Эмбеддинг: Преобразование каждого блока данных в вектор с помощью центрального процессора.
- Векторная база данных: Индексирование и хранение векторов с помощью соответствующих инструментов, например FAISS.
- Извлечение: Преобразование пользовательских запросов в эмбеддинги, чтобы выявить наиболее релевантные фрагменты документов (выборка по методу Top-K).
- Генерация: Направление данных и запроса в локальную большую языковую модель (например, llama.cpp), чтобы получить требуемый ответ.
Метрика
Наблюдаемое значение (результат реализации)
Задержки при эмбеддинге
~70–90 мс
(Оптимально для интерактивных приложений с высокой отзывчивостью)
(Оптимально для интерактивных приложений с высокой отзывчивостью)
Использование оперативной памяти (режим простоя → пиковая нагрузка на RAG-систему)
~3,5 ГБ → ~14 ГБ
(Общий рост – примерно на 10 ГБ)
(Общий рост – примерно на 10 ГБ)
Передача данных (Эмбеддинг на ЦП → генерация на ГП)
Минимальные флуктуации уровня загрузки памяти
(Не происходит копирования больших объемов данных)
(Не происходит копирования больших объемов данных)
Программный стек
FAISS (выборка) + llama.cpp (инференс)
Сюрприз №1: ЦП оказывается лучше при эмбеддинге
Считается, что графические процессоры лучше подходят для искусственного интеллекта, однако центральные процессоры ARM превосходят их в фазе эмбеддинга. В результате интерактивные запросы обрабатываются с меньшими задержками.
Графические процессоры хороши при обработке больших объемов данных, а RAG-эмбеддинг характеризуется короткими предложениями, малыми партиями и потребностью в моментальных ответах.
- Низкие задержки: Задержки при эмбеддинге на процессорах ARM составляют примерно 70-90 мс – идеально для интерактивных запросов в режиме реального времени.
- Эффективность: Используя центральный процессор, мы устраняем затраты на планирование задач графического процессора и передачу данных по шине PCIe.
- Стабильность: Обеспечивается стабильный цикл «Запрос – выборка – ответ» в приемлемых для пользователя временных рамках.
Сюрприз №2: Сила унифицированной памяти
Унифицированная архитектура памяти устраняет необходимость копирования: центральный и графический процессоры могут беспрепятственно получать доступ к одному и тому же массиву данных.
При традиционной архитектуре данные передаются, как в эстафете: копируются по шине PCIe между центральным и графическим процессорами. Унифицированная память, напротив, работает как общий гоночный трек.
- Эффективность использования ресурсов: Уровень загрузки оперативной памяти повышается с 3,5 ГБ в режиме ожидания до 14 ГБ при пиковой нагрузке на RAG-систему, что свидетельствует об эффективном использовании аппаратных ресурсов.
- Нулевое копирование: Переход от эмбеддинга на центральном процессоре к генерации на графическом процессоре не ведет к резкому повышению уровня загрузки памяти, что свидетельствует об отсутствии копирования больших объемов данных.
Сюрприз №3: Устранение AI-галлюцинаций
Технология RAG минимизирует риск получения «уверенных, но неправильных» ответов от искусственного интеллекта, поскольку теперь ответы основываются на выборке из поддающейся проверке документации.
AI-модели галлюцинируют, когда им не хватает специфических знаний, а технология RAG вынуждает их добывать доказательства, прежде чем генерировать ответ.
- Сравнительный тест: В тестах, связанных с описанием интерфейса GPIO платформы Raspberry Pi, модели без технологии RAG выдавали уверенные, но противоречивые ответы.
- Проверяемые выходные данные: С технологией RAG ответы соответствовали официальной документации – с указанием конкретных глав и таблиц.
Сюрприз №4: Десктопные AI-системы уже готовы к развертыванию
Десктопные AI-платформы прошли путь от экспериментальных прототипов до полнофункциональных решений, готовых к локальному развертыванию.
Компьютеры MSI EdgeXpert (на базе платформы DGX Spark) обладают подходящими для офиса характеристиками с точки зрения охлаждения и уровня шума, а также поддерживают полноценные программные стеки, такие как FAISS + llama.cpp.
- Контроль над данными: Все данные всегда остаются в интранете.
- Масштабируемость: Системы можно расширять, добавляя механизмы управления доступом, отчетность, выборку на разных языках.
Домашнее задание: создайте свой прототип
Для быстрой проверки локальной RAG-системы организациям следует использовать структурированную процедуру, охватывающую все этапы – от подготовки данных до оценки задержек.
- Сфера поиска: Выберите 3–5 часто задаваемых, четко обозначенных вопросов (например, параметры BIOS, инструкции).
- Подготовка данных: Подготовьте 50–200 репрезентативных документов, которые являются точными и индексируемыми.
- Индексация: Выполните консервативное разбиение на блоки (300–800 токенов) и постройте FAISS-индекс.
- Оценка: Измерьте задержки при эмбеддинге (цель < 100 мс) и точность выборки.
- Принудительное цитирование: Сконфигурируйте запрос так, чтобы требовались цитаты. Это поможет предотвратить фальсификацию.
Вопросы и ответы: технические объяснения
Вопрос №1: Почему центральный процессор быстрее при эмбеддинге? Ответ: Потому что пользовательские запросы, как правило, являются короткими и задаются малыми партиями. Используя центральный процессор, мы устраняем затраты на планирование задач графического процессора и передачу данных по шине PCIe, поэтому общие задержки уменьшаются.
Вопрос №2: В чем состоит преимущество унифицированной памяти?
Ответ: Минимизируется необходимость копировать большие объемы данных между центральным и графическим процессором, что обеспечивает плавный переход между фазами выборки и генерации.Вопрос №3: Обязателен ли для локальной RAG-системы графический процессор?
Ответ: Для фазы выборки – нет, поскольку с ней эффективно справляется центральный процессор. Однако графический процессор предоставляет существенные преимущества на последней фазе – генерации, особенно при применении крупных моделей или при необходимости повышения скорости работы.
Компьютеры MSI EdgeXpert на базе процессоров ARM – отличный выбор для создания RAG-систем. Унифицированная архитектура памяти позволяет сэкономить время на копировании данных по шине PCIe. В результате центральный процессор оказывается важнейшим компонентом периферийной AI-системы.